
Not so long ago, Google’s London-based AI unit, DeepMind, decided to take on a real challenge – beating the world’s StarCraft professionals in their own game. On Friday, January 25, we saw what has been happening in DeepMind’s HQ in London, the United Kingdom.
- DeepMind’s AlphaStar defeats StarCraft II professionals Dario “TLO” Wünsch and Grzegorz “MaNa” Komincz with 10-1
- AlphaStar plays slower than players and reacts with roughly the same speed to new developments
- The AI managed to cram 200 years of gaming in just seven days of training
AlphaStar Is Smarter than a Rat
In 2017, Facebook’s Head of AI Research, Yann LeCun, reassured people that progress in the realm of artificial intelligence wasn’t quite as impressive as luddites would have us think.
‘In terms of general intelligence, we’re not even close to a rat,’ Mr. LeCun pointed out. Fast forward to January 25, 2018, and Google has arrived to introduce chaos to the StarCraft universe.
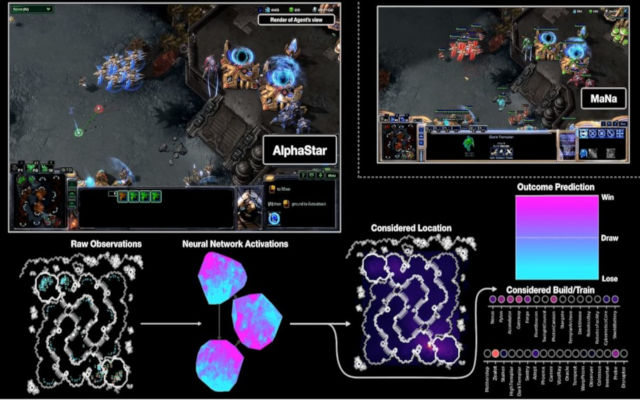
Developed in London, the United Kingdom, the DeepMind project set out to defeat the world’s best StarCraft II players.
It has succeeded.
But how did it all happen? Turns out that if you give “a rat” 200 years to plot your defeat (this is the equivalent of how much time DeepMind spent learning the game in the seven-day window), you must at least be a little worried.
Besides, rats are one of the few species to possess meta cognition, i.e. they are aware of their ability to think.
And lastly, AlphaStar is no rat. It’s an AI agent(s) with a central neural network using reinforced learning to constantly improve itself.
What Happened in London?
The DeepMind teamknew that it would need to test their brainchild against the elite of the StarCraft community. Even though the scenario was somewhat limited, with the agent(s) being able to play only Protos versus Protos, the results were quite astonishing, as the games revealed.
First, DeepMind invited Dario “TLO” Wünsch, a German Zerg player from Team Liquid. Visibly uneasy, TLO set out to face his incorporeal opponent. First game in, TLO lost, followed by four defeats. The result stood at 5-0.
That was the first test DeepMind’s AlphaStar had passed. Understandably, TLO wasn’t a Protos player, which put him at a slight, even though unlikely, disadvantage.
A Few Drinks Later – Call a Bonafide Protos
Emboldened by their success, DeepMind Head of Research, David Silver, and his team agreed to re-train DeepMind to face off a genuine professional player of the Protos persuasion. That’s when the team brought in Grzegorz “MaNa” Komincz on December 19 for the ultimate test.
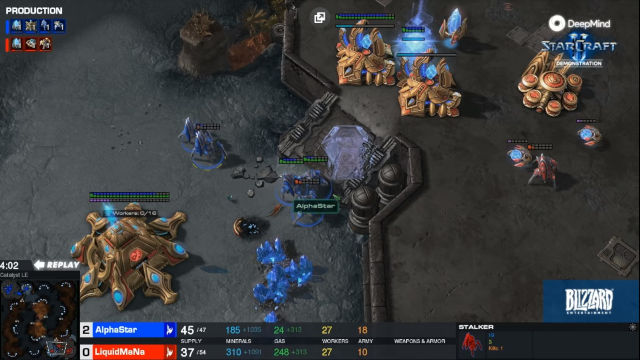
MaNa expected a realistic 4-1 in his favour, but what was an anticipated victory turned out to be a debacle with 5 games going in the way of AlphaStar.
The Science Behind It All
We can briefly outline what happened in the games, giving you the highlights of how AlphaStar (to the point where a non-expert can understand) dominated the world’s SC II elite.
Mr. Silver offered a detailed explanation and took numerous questions during the live cast on Friday, helping the audience understand how Alpha Star worked.
To start with, AlphaStar took only a week (seven days) to learn all it knew. It required for DeepMind to expedite the speed at which the game can be played, allowing the agent to cram in as much as 200 years’ worth of StarCraft experience.
Next, it was interesting how AlphaStar trained for the game. For a day or two, the machine would just watch replays, which got it up to a Platinum level, Mr. Silver said. Once there, DeepMind hosted an AlphaStar League where multiple iterations of the software played against each other.
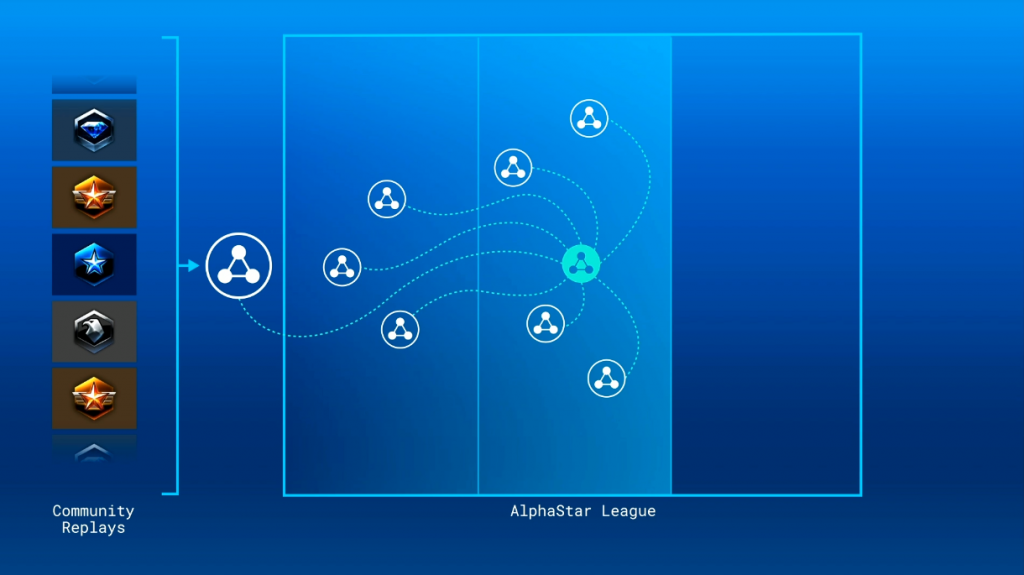
Put simply, there were multiple agents playing against TLO and MaNa – 11 in fact. Understandably, there were many questions about whether the computer was getting an unfair advantage, which were disproved by Mr. Silver.
For starters, the agents were playing “slower” than human counterparts, or at least they carried out fewer actions.
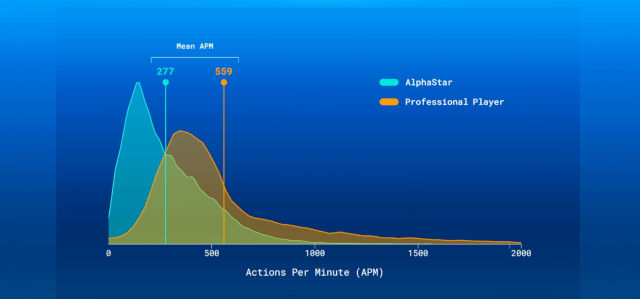
This meant that it wasn’t all necessarily about being quicker than a human in order to defeat the world’s StarCraft elite. Another important distinction was that DeepMind took roughly the same time (slower) than humans to react and assess a situation.
What then made AlphaStar so powerful? Some assumed it was the overhead view of the map that the agents had. In simple words, AlphaStar was able to perceive the entire game without having to click between screens, although assessment of a situation and execution needed to be done by going to a specific camera. Mr. Silver explained that players and AlphaStar switched roughly 30 screens each minute of a game.

So, now developers wanted to put the game to the ultimate test. MaNa came back to face off a re-trained agent. This time, DeepMind had told the agent to emulate human play and deal with situations camera-by-camera instead of having the overhead view.
When the final game came, MaNa was prepared. Pushing out of his base after surviving a costly harass, MaNa managed to pin down the AI by continuously dropping units in his main base, which forced the AI to retrieve.
Unable to come up with an effective strategy, AlphaStar got stuck in a loop, allowing MaNa to out-tech it and destroy it in one final swift attack.
MaNa has revenged humans and defended the honor of Team Liquid, but AlphaStar has learnt a new lesson.
How many before there’s nothing new to learn?








{kind=link}